OMC Consult - Qualidade e Inovação em Projetos de Supply Chain

Endereço: Av. Rio Branco, 1 / 1201 - Centro – Rio de Janeiro – RJ – cep: 20.090-907
Telefone: +55 21 2143-5759



Endereço: Av. Rio Branco, 1 / 1201 - Centro – Rio de Janeiro – RJ – cep: 20.090-907
Telefone: +55 21 2143-5759
Baseado no artigo de Sanjib Biswas e Jaydip Sen
Resumo
A Pandemia trouxe lições muito amargas para todos os profissionais de Gestão da Cadeia de Suprimentos; contudo, algumas empresas conseguiram rapidamente se reinventar e retomar bons níveis de serviço. Outras; ainda amargam baixos níveis de serviço, devido à falta ou escassez de matérias primas, fretes marítimos com custos absurdos e modelos de negócio desalinhados com o “novo normal”. Nos últimos anos, a definição de estratégia competitiva modificou-se substancialmente devido à rápida mudança da natureza do mercado global e às revoluções tecnológicas. A gestão da cadeia de suprimentos baseada em dados tornou-se uma das vantagens competitivas para as organizações, pois ajuda na integração de todas as atividades em toda a cadeia de suprimentos. Também permite que as organizações tomem decisões estratégicas informadas, ao mesmo tempo em que mitigam riscos em ambiente de negócios incerto. Os dados estão sendo gerados a partir de todas as etapas de uma cadeia de suprimentos, resultando em volume gigantesco de dados de natureza diversificada, desde dados transacionais até opiniões subjetivas dos clientes. A Análise desempenha um papel significativo no tratamento do “Big Data” hoje e será de importância crescente amanhã. A edição deste mês, discutirá a relação da nova geração da cadeia de suprimentos e a utilização das fontes de geração de dados, sua natureza e o volume dos dados gerados e consumidos. Espero que gostem.
1. Introdução
A Price Waterhouse realizou estudo (em junho e julho de 2020 como uma extensão da “Pesquisa Anual global de CEOs) representando pequenas e grandes empresas, empresas privadas e públicas, e uma seção transversal diversificada de indústrias, países e regiões em todo o mundo. O estudo mostra que, embora as empresas tenham tomado várias medidas de curto prazo para combater as consequências iniciais do bloqueio econômico e social, as soluções que se destacaram com efeito de longo prazo foram, infraestrutura digital, digitalização de produtos e serviços e modelos de trabalho flexíveis e seguros.
Como dito acima, a pandemia rapidamente forçou as empresas a revisar seus modelos e processos de negócios e testar novas oportunidades de receita. Os desafios mais imediatos enfrentados pelos executivos foram a incapacidade de conduzir negócios pessoalmente ou no local. Por um lado, eles tinham que ter certeza de que os funcionários poderiam trabalhar remotamente; por outro lado, eles precisavam permitir o acesso do cliente a produtos ou serviços sem interações físicas. E algumas dessas mudanças fundamentais estão aqui para ficar.
A pesquisa mencionada aponta que para 61% dos entrevistados, a digitalização está entre as três principais questões. A criação da infraestrutura digital de uma empresa ou o aprimoramento de suas capacidades digitais abrange não apenas fatores tecnológicos, mas também culturais, e deve ser apoiado desde o início. Após o COVID-19, os modelos de negócios também serão mais digitais à medida que a colaboração remota se tornar o novo normal.
O conceito e as práticas de gestão da cadeia de suprimentos (SCM) ganharam importância como fonte de vantagem competitiva para as organizações desde o final dos anos 80. Com o passar do tempo, o rápido desenvolvimento tecnológico impôs maior desafio à gestão das cadeias de suprimentos para alavancar o crescimento dos negócios.
Um ciclo de vida mais curto do produto e a exigência de produtos e serviços inovadores obrigaram as organizações a operar com extrema eficiência do projeto à entrega, adicionando-se flexibilidade e economias em um ambiente de negócios volátil e altamente competitivo. Para manter a agilidade e a receptividade às mudanças nas necessidades do mercado, a sinergia horizontal é fundamental para o sucesso de qualquer cadeia de suprimentos.
Por isso, as relações de desempenho em toda a cadeia de suprimentos dependem em grande parte de como os membros coordenam e colaboram entre si; para formular estratégias e operar para alcançar objetivos globais, requerendo integração de sistemas internos e externos. Desnecessário dizer que, o compartilhamento de informações entre os membros de uma cadeia de suprimentos é de suma importância hoje.
O desenvolvimento em tecnologia da informação e comunicação (TIC) deu origem à geração de enorme quantidade de dados que estão distribuídos em toda a cadeia de suprimentos fornecendo às organizações uma oportunidade sem precedentes para formular estratégias consolidadas e, desnecessário afirmar que, gerenciar um volume tão grande de dados (“big data”) é uma tarefa assustadora. Em primeiro lugar, a compreensão da geração de dados é absolutamente importante. Em seguida, é importante processar os dados para extrair informações úteis relativas ao SCM. A análise, portanto, desempenha um papel crucial no apoio à tomada de decisões para melhorar o desempenho de uma cadeia de suprimentos.
2. Cadeias de suprimentos e análises orientadas por dados
De acordo com a definição tradicional – cadeia de suprimentos é uma rede integrada por meio de elos (desde os fornecedores aos clientes) downstream e, (desde os clientes aos fornecedores) upstream, nos diferentes processos e atividades que produzem valor na forma de produtos e serviços entregues ao consumidor final.
Essencialmente, qualquer cadeia de suprimentos consiste em quatro processos integrados como, planejamento, aquisição, produzir e entregar através de um fluxo engenheirado de materiais, informações e recursos. Inclui-se também a logística reversa levando em conta o feedback do cliente, informações sobre o desenvolvimento de novos produtos e o retorno do produto.
O desempenho da cadeia de suprimentos é medido com base no modelo de referência de operações da cadeia de suprimentos (SCOR), que inclui o planejamento, definição de metas, monitoramento e controle. Esse modelo define essencialmente prioridades competitivas de uma cadeia de suprimentos. Muitos pesquisadores e profissionais têm estudado sobre processos da cadeia de suprimentos para entender e identificar o tipo de geração de dados em toda a cadeia. Estudos relataram que, a análise dos dados relativos ao nível de estoque, vendas, cronograma de produção e entrega, métricas de desempenho como qualidade, tempo de reposição, capacidade de processo, previsão de demanda, tendência de mercado, disponibilidade de transporte, custo operacional, promoção e branding, base de fornecedores etc. são importantes na compreensão e controle das operações da cadeia de suprimentos para o aumento da rentabilidade e redução de custos.
No nível de planejamento, são analisados dados relativos às demandas e tendências do mercado e tomadas decisões operacionais adequadas, incluindo o design de produtos e serviços. Neste nível, dados de pontos de vendas (PDV), geração de receita, status de crédito, desconto, status do pedido, previsão de vendas, dados dos concorrentes, necessidades e preferências do cliente, dados relacionados a produtos substitutos e complementares etc. são capturados e analisados.
A natureza dos dados é parcialmente transacional e parcialmente subjetiva e essas informações desempenham um papel crucial na compreensão da pegada da organização no mercado. A amplificação de informações de demandas distorcidas (efeito chicote) resulta em nível de estoque incomparável, utilização inadequada da capacidade, compras inadequadas, variações na entrega, logística desequilibrada, uso indevido de fundos que levam ao custo de oportunidade, preços ineficazes e subutilização da habilidade. Além disso, afeta a confiabilidade do fornecedor e a qualidade do atendimento ao cliente.
Ao nível da aquisição (sourcing), são registrados e analisados dados relativos à seleção e avaliação do fornecedor, ordem de compra, custo do ciclo de vida, logística de entrada, nível de estoque, armazenamento de material etc. esse nível estabelece a base de um SCM eficaz. A análise (analytics) tem aplicações significativas na formulação da política de estoque ideal, na configuração aumentar a conectividade com fornecedores globais, na decisão sobre o cronograma de produção abrangente e na garantia de fluxo equilibrado para responder às necessidades em mudança do mercado
Consequentemente, a análise de dados relacionados ao sequenciamento das operações, cronograma de produção, tempo de reposição, tempo de processo, qualidade, capacidade de processo, eficácia e disponibilidade geral do equipamento, estoque em processamento (WIP) etc. garantem fluxo ininterrupto ao eliminar resíduos.
Finalmente, a análise também impacta criticamente a logística de saída, o tempo de reposição, a localização das instalações e a gestão das devoluções. Isso, por sua vez, ajuda na otimização geral dos custos e melhora a eficiência geral da cadeia de suprimentos.
A Figura 1 retrata a estrutura de uma cadeia de suprimentos típica e a Tabela 1 exibe várias fontes de geração de dados em toda a cadeia de suprimentos.
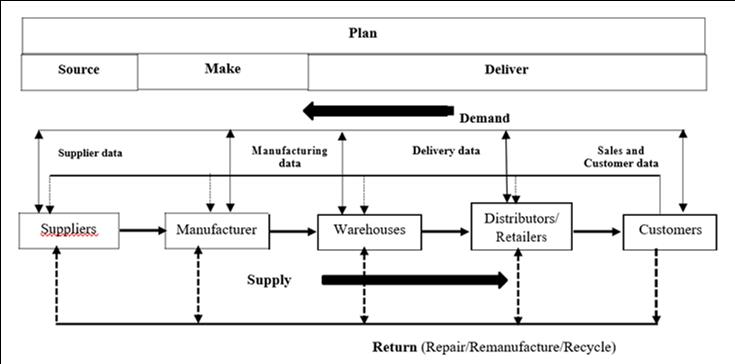
Movimento para frente – Fluxo do suprimento (materiais) Fluxo de recursos
Return path – Flow of return (materiais) Flow of data (information)
Assim, a Análise da Cadeia de Suprimentos (SCA) constrói capacidades competitivas para as organizações para alcançar a excelência empresarial sustentável. No entanto, é importante notar que, uma cadeia de suprimentos madura que é impulsionada pela análise requer gestão de dados, gerenciamento de processos e gerenciamento de desempenho, tudo com igual importância [12]. Um ambiente agradável informativo requer essencialmente compreensão e armazenamento de dados, análise dos resultados e compartilhamento de informações para previsão colaborativa e planejamento para o crescimento de negócios de longo prazo [13]. A integração dos membros em uma cadeia de suprimentos requer essencialmente a integração de pessoas e organizações nas quais a TI atua como um facilitador-chave [14].
3. Big data e seu impacto no SCM
Em termos simples, ‘big data’ refere-se a uma quantidade volumosa de dados que não podem ser armazenados, processados e gerenciados por um sistema convencional de gerenciamento de banco de dados. Essencialmente, abrange dados estruturados e não estruturados da ordem de Zettabyte ou até mais. De acordo com Sen, “as tecnologias big data (Intensiva em Dados) estão visando processar dados de alto volume, alta velocidade e alta variedade (conjuntos/ativos) para extrair o valor dos dados pretendidos e garantir a alta veracidade dos dados originais e obter informações que exigem formas econômicas e inovadoras de processamento de dados e informações (analytics) para maior percepção, tomada de decisões e controle de processos; toda essa demanda (deve ser suportada por) novos modelos de dados (suportando todos os estados e estágios de dados durante todo o ciclo de vida dos dados) e novos serviços e ferramentas de infraestrutura que permitem também a obtenção (e processamento de dados) de uma variedade de fontes (incluindo redes de sensores) e a entrega de dados em uma variedade de formulários para diferentes dados e informações consumidores e dispositivos” [15]. Caracteristicamente é apresentado por cinco ‘V’: i) volume (quantidade de dados sendo gerados), ii) velocidade (velocidade na qual é gerado), iii) variedade (retrata a natureza diversificada dos dados que estão sendo gerados), iv) valor (utilidade intrínseca dos dados que estão sendo gerados) e v) veracidade (correção inerente sujeita à variação). No entanto, mantendo a natureza mutáveis dos dados e as ligações entre várias mudanças ao longo do ciclo de vida, mais dois recursos são adicionados, como dinâmica de dados e vinculação.
Para manter o crescimento sustentável e alcançar resultados de negócios inclusivos, não basta apenas que as organizações entendam o que aconteceu e por que isso aconteceu (ação corretiva) e, em seguida, tomem ações adequadas para o futuro (ação preventiva). Em vez disso, as organizações precisam se concentrar no que está acontecendo agora e no que vai acontecer para prever o futuro nas incertezas para tomar a decisão apropriada. Waller e Fawcett mencionaram que, “as análises preditivas da SCM utilizam métodos quantitativos e qualitativos para melhorar o design e a competitividade da cadeia de suprimentos, estimando níveis passados e futuros de integração dos processos de negócios entre funções ou empresas, bem como os custos e níveis de serviço associados” [16]. Assim, o SCM de próxima geração depende em grande parte de uma compreensão adequada dos dados diversificados e volumosos que estão sendo gerados nas cadeias de suprimentos e, em seguida, extrair informações úteis dos dados, a fim de auxiliar na tomada de decisões estratégicas “informadas”, aproveitando o poder da análise. No contexto do SCM, a big data desempenha um papel significativo no desbloqueio de novas fontes de valor de negócio [17]. A Tabela 2 resume a utilidade das análises no contexto do SCM.
I. Volume
a. Fornecedor: Mais detalhes em torno de dados de projeto para produtos, tipo de produtos, processo, pedido, estoque, tamanho do lote, entrega, tempo de entrega, embarque e roteamento, preços, impostos, pagamento, devolução/descarte.
b. Fabricação: Design do produto, exigência do cliente (por exemplo, especificação, escolha, demanda, pedido, tempo de entrega, feedback), métricas de processo (por exemplo, tempo de transferência, tempo de ciclo, % de rejeição, capacidade, confiabilidade, manutenção), planejamento e agendamento de produção, inventário (por exemplo, tamanho do lote, pedido, produto em elaboração (WIP), sucata/descarte, bens acabados, matéria-prima), armazenamento de materiais, embarque e roteamento, dados do fornecedor (por exemplo, lista de fornecedores, dados de compra, avaliação do fornecedor, tempo de entrega), dados de pessoas (por exemplo, inventário de habilidades, dados de treinamento, detalhes de implantação), dados financeiros (por exemplo, salário, custo de conversão)
c. Entrega: Dados de demanda (por exemplo, pedido, variedade, previsão), tempo de entrega, cronograma de entrega, dados de localização, estoque (por exemplo, nível de estoque, dados de envelhecimento), envio e roteamento (por exemplo, modo de transporte, carga, rede e caminho), dados financeiros (por exemplo, preços, taxa de câmbio, imposto, pagamento), diversos (por exemplo, clima, dados sociais, econômicos, regionais), dados do cliente (por exemplo, escolha, feedback), dados de fabricação (por exemplo, status de estoque, plano de produção e, detalhes do produto), dados de vendas (por exemplo, promoção, dados de PDV), devolução/eliminação.
d. Vendas e Cliente: Dados do Ponto de Vendas (PDV), status do pedido, dados de demanda, dados do cliente (por exemplo, produto, quantidade, entrega, lead time, sentimentos, feedback, novo produto, perfil, escolha, padrão de compra), promoção, dados financeiros (por exemplo, pagamento, preços, desconto, câmbio), embarque e roteamento, retorno/descarte
II. Velocidade:
a. Fornecedor: Por hora, diariamente, semanal, mensal, anual
b. Manufatura: Por hora, diariamente, semanal, mensal, anual
c. Entrega: Tempo real, horário, diário, semanal, mensal, anual
d. Vendas e Cliente: Tempo real, hora, diária, semanal, mensal, anual
III. Variedade:
a. Fornecedor: Vários bancos de dados, web, áudio (verbal/telefônico), E-e-mail,
b. Fabricação: documento físico, dados do sensor, dados RFID Documento físico, dados do sensor, dados RFID, câmera, vários chips, dados da Web, e-mail
c. Entrega: Documento físico, dados do sensor, dados RFID, E-mail, vários bancos de dados, web, áudio (verbal/telefônico)
d. Vendas e Cliente: Documento físico, dados do sensor, dados RFID, E-mail, vários bancos de dados, web, áudio (verbal/telefônico).
IV. Valor:
a. Fornecedor : Desenvolvimento eagendamento de novos produtos, planejamento e agendamento de produção, ótimo tamanho do lote e planejamento de estoque, envio e roteamento, descarte/reciclagem.
b. Fabricação: Ótimo tamanho do lote e planejamento de estoque, decisão do produto, seleção de processos, execução e controle, planejamento e agendamento de produção, seleção de fornecedores, otimização do lead time de entrega, decisão de roteamento, remanufatura/reciclagem/eliminação
c. Entrega: Planejamento de transporte e rede, planejamento de loja, planejamento de estoque, análise do cliente
d. Vendas e Cliente: Modelagem preditiva da demanda, análise do cliente, planejamento de rede, planejamento de cestas de mercado, planejamento de sortimento, branding e promoção.
V. Veracidade: Múltiplas fontes de dados, diferentes formatos, falta de confiabilidade em algumas fontes de dados, presença de ruído na comunicação da rede.
VI. Análise:
a. Fornecedor: Mineração de regras de associação, otimização, planejamento de rede, logística e planejamento da cadeia de suprimentos, Análise de Sentimentos, planejamento de estoque
b. Manufatura: Otimização, pesquisa de operações, planejamento de atribuição e cronograma, desenvolvimento de novos produtos, planejamento de estoque, distribuição e planejamento de armazéns, análise de sentimentos, previsão, modelagem preditiva de demanda
c. Entrega: Planejamento logístico e de distribuição, planejamento de rede, seleção de varejistas,
d. Vendas e Cliente: Análise de sentimento, previsão de análise de sentimento, análise de cesta de mercado, previsão, planejamento de layout de prateleira de produtos.
Nota: No que diz respeito aos fornecedores, os 5 Vs podem não mudar em grande medida, mas, no caso de produtos fornecidos pelos fornecedores, pode ocorrer variação significativa.
4. Uma arquitetura baseada em nuvem de sistemas de big data para SCM
Nesta seção, uma estrutura SCM habilitada para big data é proposta. O objetivo do sistema é fazer uma tentativa de integrar perfeitamente a geração, aquisição, limpeza (pré-processamento), gerenciamento de armazenamento, análise e visualização de big data em etapas de uma cadeia de suprimentos. A proposta é genérica nesta fase. No entanto, uma estrutura mais otimizada para a aplicação do mundo real evoluirá no futuro, à medida que implementamos os componentes do sistema. Figura 2. Big data impulsionado na estrutura da cadeia de suprimentos de próxima geração
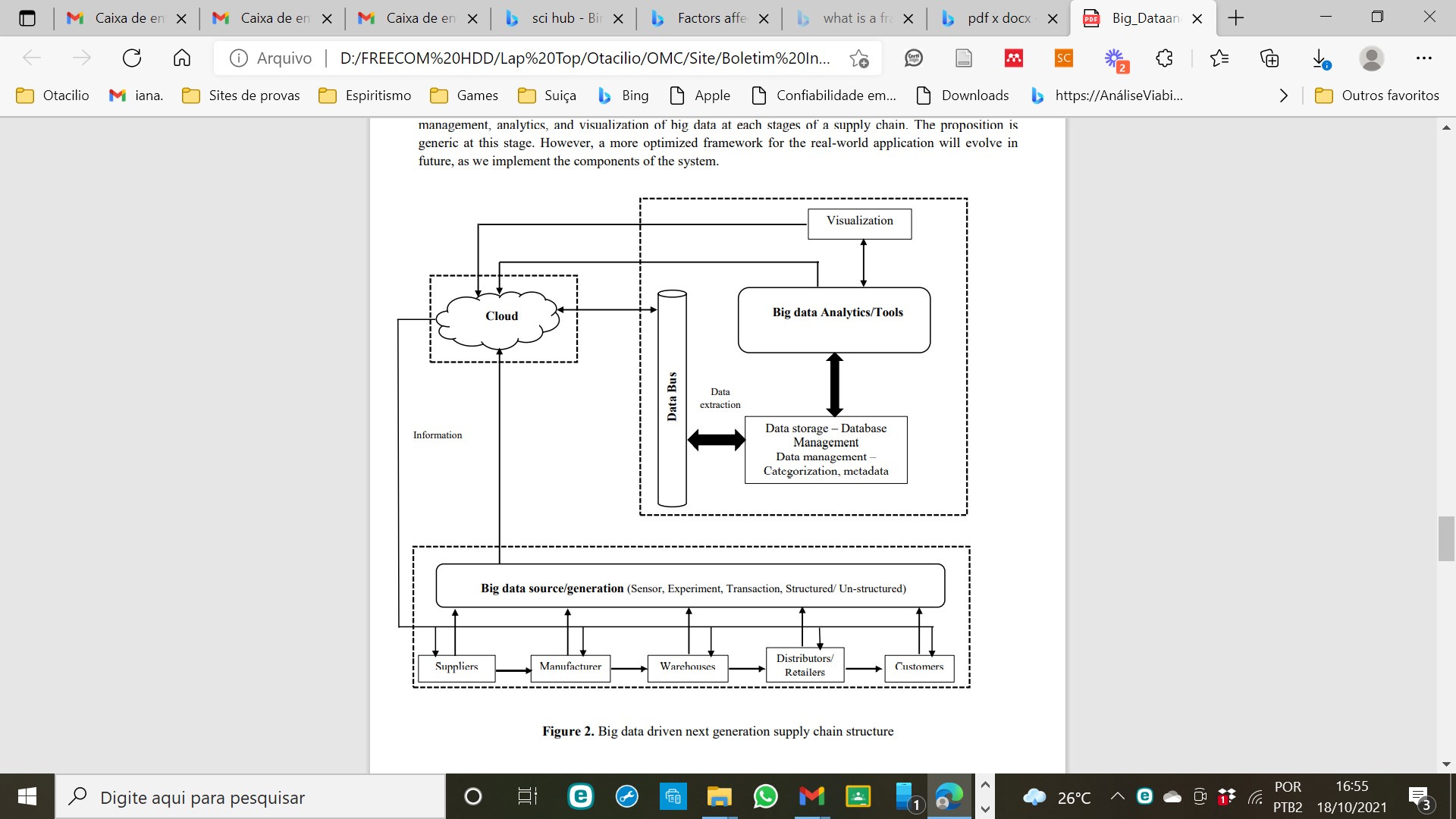
Em um sentido amplo, a arquitetura proposta consiste nos seis componentes: (i) Dispositivos de aquisição de sensores e outros dados, (ii) Infraestrutura em nuvem, (iii) Data bus, (iv) Armazenamento de dados e gerenciadores de sistema, (v) mecanismo de análise de dados, (vi) sistema de visualização e renderização de dados.
• Sensores e outros dispositivos de aquisição de dados: Este sistema inclui todos os objetos e dispositivos responsáveis pela coleta de dados brutos em cada estágio de uma cadeia de suprimentos. Vários sensores, atuadores, objetos habilitados para tag RFID, objetos conectados à câmera e os objetos que são endereçados no paradigma da Internet das Coisas (ou seja, que têm endereços IPv6) servirão como fonte de dados [18]. É possível rastrear qualquer objeto em uma cadeia de suprimentos, desde que tenha um endereço e um pequeno sensor ligados a ele. Com os custos decrescentes do sensor e seus tamanhos ficando menores ao longo do período, agora é economicamente viável ter tais sensores ligados em cada lote de materiais (incluindo crus, semiacabados e acabados) senão em cada produto individual. Embora ele nos forneça a oportunidade de rastrear o status de cada objeto em uma cadeia de suprimentos, há também um desafio em lidar com o volume gigantesco de dados gerados a partir de tal situação. No entanto, com o paradigma de computação de última geração atual, como a computação em nuvem, o processamento distribuído, o processamento paralelo e com a disponibilidade de dispositivos de hardware extremamente rápidos e algoritmos inteligentes, não é mais impossível enfrentar esse desafio. Os dados gerados a partir dos objetos individuais são passados por cima da nuvem através de vários dispositivos de gateway colocados em locais adequados, nas instalações de fabricação e logística dos fornecedores, fabricantes, distribuidores, varejistas e clientes finais.
• Infraestrutura em nuvem: Os dados gerados pelos objetos de origem são passados sobre a nuvem. A nuvem é uma coleção de instalações de computação e armazenamento pela Internet que fornece uma solução de baixo custo para a necessidade dinâmica de armazenamento e processamento. Os dados brutos gerados pelas fontes são armazenados em vários servidores e podem ser possivelmente replicados. A replicação dos dados proporciona alta robustez e maior disponibilidade do sistema.
• Data Bus: Os dados da nuvem são recebidos no barramento de dados do sistema com base no tipo de dados em contexto. Os dados que precisam de tempo real de processamento e análise são encaminhados através da nuvem para o barramento de dados de tal forma que haja um atraso mínimo, enquanto outros dados só podem ser transferidos quando necessário para processamento e análise. Isso é cuidado pelo protocolo de roteamento embutido no sistema de comunicação DATA. O barramento de dados deve ter capacidade de armazenamento temporária adequada para lidar com o grande volume de dados que podem precisar de processamento em tempo real.
• Sistema de armazenamento e gerenciamento de dados: O sistema de barramento de dados passa os dados para o sistema de armazenagem de dados, que inclui um grande sistema de gerenciamento de banco de dados com todos os recursos, como indexação, buffering e otimização de consulta em tempo real. Esse sistema também é responsável pelo pré-processamento de dados e limpeza de dados. Em outras palavras, a principal funcionalidade do sistema de armazenamento e gerenciamento de dados é processar e converter os dados brutos em um formulário que pode ser processado de forma muito eficiente pelo mecanismo de análise.
• Mecanismo de Análise de Dados: O coração de todo o sistema é o mecanismo de análise de dados. O mecanismo de análise de dados inclui algoritmos de processamento inteligente para extrair eficientemente informações significativas e valiosas do streaming bruto ou dados estáticos. Este sistema é equipado com um subsistema de construção de conhecimento que lhe permite aprender com os rules existentes nos sistemas atuais e, em seguida, construir novas regras. Essas novas regras permitem que o mecanismo de análise tome decisões inteligentes em situação incerta ou na ausência de alguns dados brutos em determinadas aplicações de análise preditiva.
• Visualização de dados e Sistema de Renderização: Como o volume de dados é muito grande, na maioria das vezes é impossível fazer qualquer análise em tempo real, na ausência de um sistema eficaz de visualização e renderização de dados. O objetivo do sistema de visualização de dados é fazer uma representação visual dos resultados da análise para que a decisão apropriada possa ser tomada instantaneamente. Na maioria das vezes, as decisões podem ser tomadas pelo sistema com base em seu entendimento atual e conhecimento das regras. No entanto, o usuário pode intervir, se necessário, e anular a decisão tomada pelo sistema.
Para que o sistema acima funcione de forma eficaz, a sincronização de todos os componentes, é fundamental garantir um alto nível de sua disponibilidade, robustez e interoperabilidade dos subsistemas. Para alcançar o alto nível de disponibilidade do sistema, a maneira mais prática é replicar os componentes do sistema. No entanto, a replicação envolve custos exorbitantes às vezes. Assim, é necessária uma compensação para equilibrar o sistema operacional, o custo fixo e os custos de possível inatividade do sistema. A robustez e a interoperabilidade dos componentes do sistema também podem ser aumentadas usando o estado do hardware. No entanto, uma troca apropriada também é necessária aqui.
5. Escopo futuro do trabalho
A arquitetura apresentada neste artigo tem a capacidade de reunir, pré-processo, limpar, analisar e representar visualmente os resultados da análise de quaisquer aplicações que envolvam big data. No entanto, também focamos nossa atenção em um cenário de aplicação dere-mundo complexo específico, o gerenciamento da cadeia de suprimentos. Assim, seria ainda mais eficiente que a arquitetura fosse projetada de tal forma que, em vez de tratar o sistema de big data e o sistema da cadeia de suprimentos como sistemas independentes separados, interagindo entre si, um sistema perfeitamente integrado combinando ambos pode ser projetado. A tarefa envolvida será complicada pelo fato de que a sincronização do sistema e a otimização de desempenho imporão um grande desafio. Isso vai prover uma boa oportunidade de futuro escopo de trabalho.
6. Conclusão
Este artigo apresentou uma visão panorâmica de dois paradigmas importantes do mundo real: cadeia de suprimentos e análise de big data. Em primeiro lugar, uma discussão detalhada sobre a próxima geração da cadeia de suprimentos foi feita com especial foco em suas várias etapas. Em seguida, foi apresentado o contexto do big data e sua relevância na gestão da cadeia de suprimentos. Também foi apontado como o gerenciamento e a análise de big data impactariam a eficiência e a operação de um complexo sistema de cadeia de suprimentos. Foi proposta uma arquitetura distribuída que aproveita o benefício da análise de big data em uma estrutura típica da cadeia de suprimentos. Um futuro escopo de trabalho para projetar uma arquitetura perfeita que integrará os dois diversos e complexos sistemas de big data e cadeia de suprimentos também foi destacado.
Referências:
[1] Yan, J., Xin. S., Liu, Q., Xu, W., Yang, L., Fan, L., Chen, B. and Wang, Q. (2014) “Intelligent Supply Chain Integration and Management Based on Cloud of Things”, International Journal of Distributed Sensor Networks,1-15.
[2] Dong, S., Xin Xu, S. e Zhu, K.X. (2009) “Tecnologia da Informação em Cadeias de Suprimentos: O Valor dos Recursos Habilitados para TI sob concorrência”, Pesquisa de Sistemas de Informação, 20(1), 18 -32.
[3] Sahin, F. e Robinson, E.P. (2002) “Coordenação de Fluxo e Compartilhamento de Informações nas Cadeias de Suprimentos: Revisão, Implicações e Direções para Pesquisas Futuras”, Ciências de Decisão,33(4), 1 – 32.
[4] Salo, J. e Karjaluoto, H. (2006) “TI — Gestão da cadeia de suprimentos habilitada”, Pesquisa de Gestão Contemporânea,2(1), 17-30.
[5] Khan, R. (2013) “Business Analytics and Supply Chain Performance: An Empirical Perspective”,
International Journal of Operations and Logistics Management, 2(3), 43 -56.
[6] Christopher, M. (1992) Gestão de Logística e Supply Chain,Pitmans, Londres, Reino Unido.
[7] Sahay, B.S. e Ranjan, J. (2008) “Inteligência de Negócios em Tempo Real em Análise da Cadeia de Suprimentos”, Gestão da Informação & Segurança deComputadores , 16 (1), 28-48.
[8] Cai, J., Liu, X., Xiao, Z. e Liu, J. (2009) “Melhorando o Gerenciamento de Desempenho da Cadeia de Suprimentos: Abordagem Sistemática para Analisar a Realização iterativa do KPI”, Sistemas de Apoio à Decisão,46 (2), 512-521.
[9] Lee, H.L. e Whang, S. (2000) “Compartilhamento de Informações em uma Cadeia de Suprimentos”, International Journal of Manufacturing Technology and Management,1(1), 79 – 93.
[10] Hoole, R. (2005) “Cinco maneiras de simplificar sua cadeia de suprimentos”, Supply Chain Management: An International Journal, 10 (1), 3-6.
[11] Clark, A. e Scarf, H. (1960) “Políticas ideais para um problema de inventário multi-escalão”,
Ciência da Gestão, 6, 465 – 490.
[12] Chae, B. e Olson, D.L. (2013) “Business Analytics for Supply Chain: A Dynamic-Capabilities Framework”, International Journal of Information Technology & Decision Making,12(1), 9 -26.
[13] Raghu, T.S. e Vinze, A. (2007) “Um Contexto de Processo de Negócios para Gestão do Conhecimento”, Sistemas de Apoio à Decisão, 43 (3), 1062-1079.
[14] Lockamy III, A. e McCormack, K. (2004) “Vinculando práticas de planejamento do SCOR ao desempenho da cadeia de suprimentos, um estudo exploratório”, International Journal of Operations & Production Management,24(12), 1192 – 1218.
[15] Sen, J. (2015) “Arquitetura de Big Data Ecosystem para Aplicações Empresariais”, CBS Journal of Management Practices, 2(1), 21 – 40.
[16] Waller, M.A. e Fawcett, A.C. (2013) “Data Science, Predictive Analytics e Big Data: A Revolução Que transformará o design e a gestão da cadeia de suprimentos”, Journal of Business Logistics,34(2), 77-84.
[17] Robak, S., Franczyk, B. e Robak, M. (2013) “Aplicando Conceitos de Big Data e Dados Vinculados na Gestão de Cadeias de Suprimentos”, Proceedings of the Federated Conference on Computer Science and Information Systems,1203-1209.
[18] BandyOpadhyay D., e Sen, J. (2011) “Internet das Coisas: Aplicações e Desafios em Tecnologia e Padronização”, Comunicações Pessoais Sem Fio (Edição Especial sobre Clustering em Nuvem Distribuída e Segura),58(1), 49-69.
© OMC Consult Ltda.
Desenvolvimento: ![]()